
# High Performance Computing
![]()
Damavand is written to support computations on conventional laptops or HPC architectures. Here, we describe the distributed implementation and provide with some scripts to start with.
# Distributed CPU
First, let us pass through the distributed CPU implementation. Consider that you have access to a supercomputer, or an architecture that supports multiple nodes. One advantage of this is that quantum circuit simulations are memory bound. This means that the computation bottleneck does not reside on the operations - that are pretty simple - but rather on how to store the excessive amount of memory required to simulate a quantum state.
As shown in the illustration below, condier that the state vector can be splitted into a fixed number N. It is then straightforward to assign each chunk of the state vector to a different node.
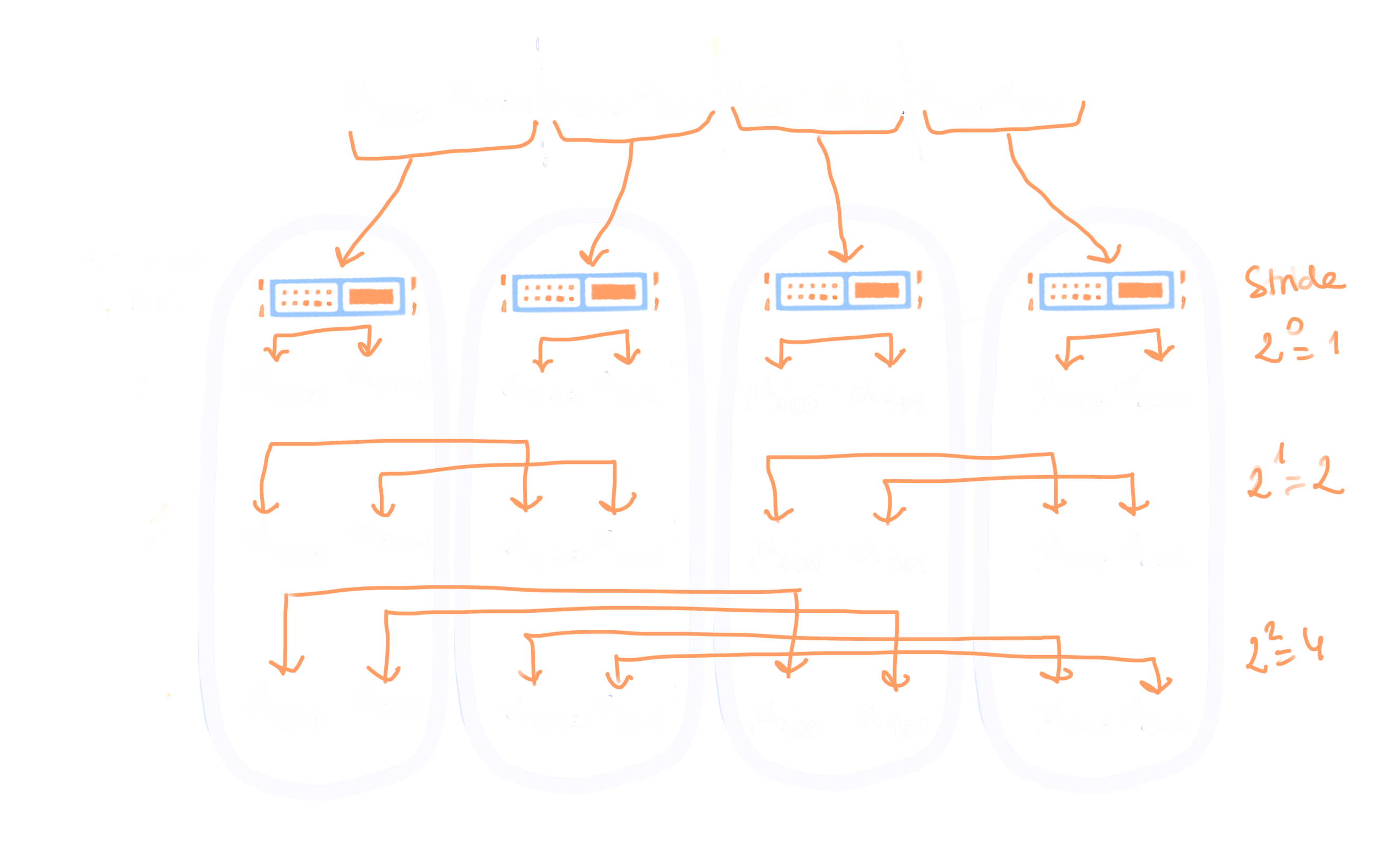
Each node is built with a certain number of processors, thus allowing to run multithreaded experiments. However, referring to the multithreading implementation presented in Guide, we can infer that some communications will be required between distant nodes to share a part of the state vector. Indeed, the stride between two amplitudes is necessarily of length 2^k, where k is the target qubit on which one wants to perform some operation.
Damavand implements an MPI scheme in order to share this information across multiple nodes.
# Distributed GPU
Another possibility is to leverage architectures - mainly built to support Artificial Intelligence applications - composed of multiple nodes, each containing multiple GPUs. As seen in the Guide section, the single GPU implementation is almost straightforward, and although some optimizations could be further thought of, it is reasonable to consider the multi GPU implementation. We focus on CUDA (opens new window) capable devices, thus restraining the developments to Nvidia hardware.
In the case of a supercomputer, the GPUs on the same node will often allow direct inter device communications through high thoughput NVLinks.
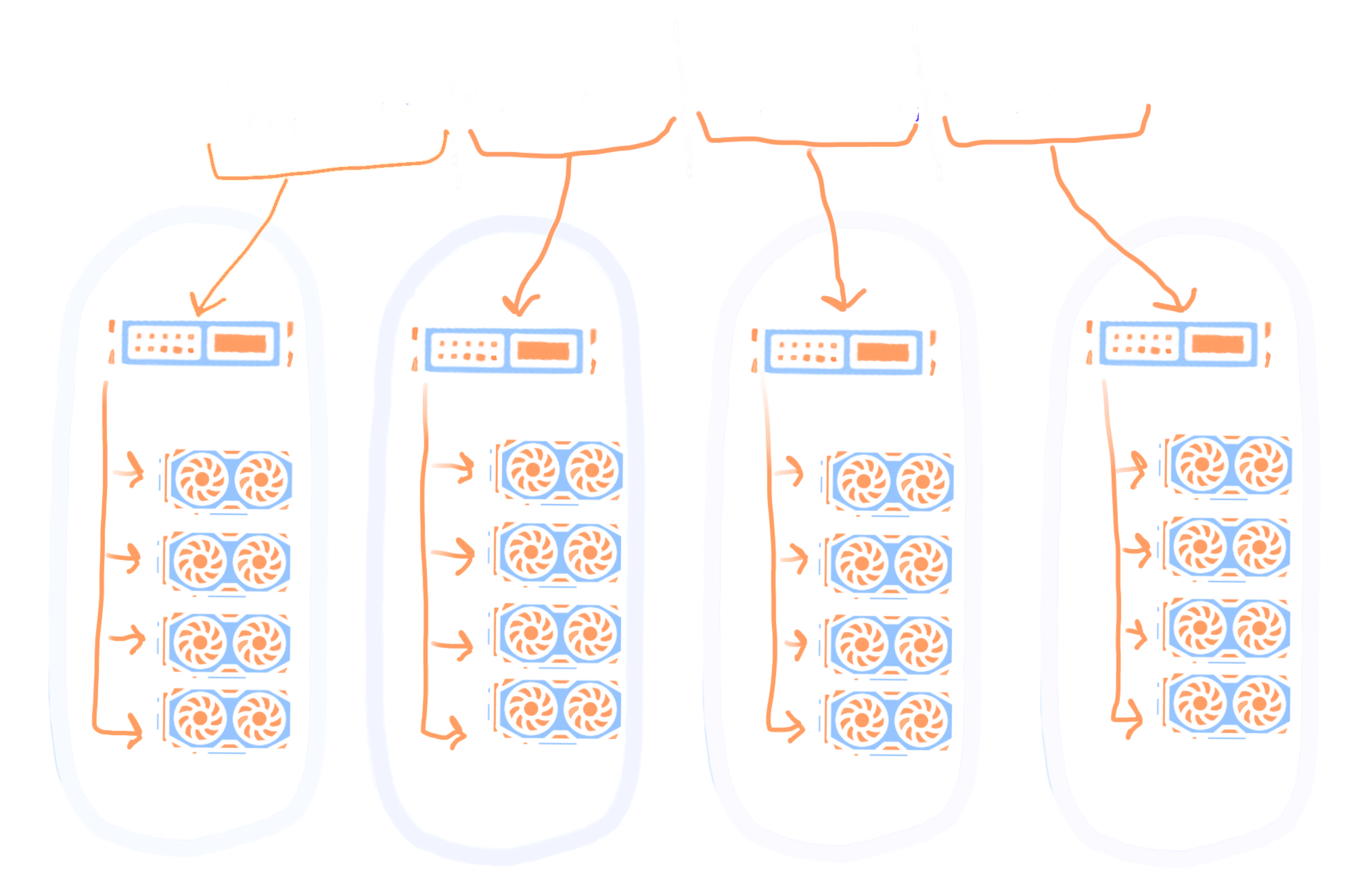
The illustration above shows that memory can be loaded on from the CPUs to the GPUs. We choose to treat inter-node communications with MPI (OpenMPI (opens new window) or MPICH (opens new window)).
# Slurm scripts
#!/bin/bash
#SBATCH --job-name=two_nodes
#SBATCH --qos=qos_cpu-dev
#SBATCH --ntasks=2
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=40
#SBATCH --output=two_nodes.listing
#SBATCH --time=5:00
module purge
module load openmpi/3.1.4
module load cuda/10.2
srun python3 two_nodes.py
# Experimentations on Jean-Zay
